This is the detailed production setup. With the help of our instructions below, you can quickly, easily and conveniently perform your own installation of the croit Ceph Storage Management Software. Our software will lead you to a functional Ceph Cluster with a few steps after the first start.
After the initial installation of your cluster, our software is available to you for 30 days free of charge under the Enterprise license for evaluation/PoC purposes. After the first 30 days, you can purchase the license from us, or continue to use the functionality of the free Community Edition.
Please provide feedback, using our contact form or send us an e-mail to: feedback@croit.io.
REFERENCE SETUP
NEED HELP WITH A SETUP?
Our consultants are happy to discuss possible networks and assist with all steps of the setup including network planning, hardware selection, and actual deployment.
We have deployed croit on a variety of server and network hardware. Contact us for a solution tailored to your requirements.
MANAGEMENT NODE REQUIREMENTS
We suggest the following minimum hardware requirements for the management node.
- minimum of 8 GB RAM, more is better
- min 100 GB SSD space (Statistics and log files)
- at least 4 CPU cores
- any Linux operating system, we suggest the latest debian at the moment
- Docker
- good Internet connection
- dedicated network access to Ceph hosts
Besides that, it is absolutely important to
- have no firewall that prevents our software from accessing the Internet on outbound HTTP and HTTPS as well as unrestricted access from and to the Ceph network. If you like to place a firewall between the Management Node and the Ceph Network, please consult our technical service, but we strongly advise against it.
- ensure that no NTP Service is running on the management node, as our docker container brings its own NTP. Some linux distributions have an NTP enabled by default, so please check that before running our software. For most operating systems,
timedatectl set-ntp offwould help to do so. - disable SELinux if you want to use a Linux Distribution with SELinux, or start our software with the additional parameter
--security-opt label:disableto avoid problems.
Network setup
In order to use croit, all your storage servers need access to a dedicated network in which croit provides DHCP PXE boot.
Avoid installing croit within the same layer 2 network as your other servers or desktop systems. croit features full support for VLAN tagging for network segmentation.
We suggest using two different networks for production setups. The management network connects the management node to the Ceph servers and is used for PXE boot and administrative traffic. This network does not need to be accessible from the outside.
The Ceph network is used for Ceph cluster traffic and client traffic alike. This network can also be split into two dedicated networks for cluster traffic and client traffic. The network serving client traffic needs to be reachable from all storage clients and the management node.
You can use switches of your preferred network vendor, we have successfully deployed croit with a variety of switch vendors including Arista, Juniper, and Cisco.
Note: When using Cisco switches, we recommend to enable the fast-booting feature on all ports used for PXE booting croit servers.
The full list of network requirements are:
- Management network
- 10 Gbit/s (but it can work with 1 Gbit/s as well)
- Redundant (LACP) strongly recommended
- Untagged (access port) at the Ceph nodes to facilitate PXE boot
- Layer 2 connectivity or DHCP relay between management node and storage servers
- Ceph network
- >= 2x 10 Gbit/s (25 Gbit/s suggested)
- Redundant (LACP) strongly recommended
- Layer 3 connectivity between all storage nodes and clients
- Nodes running Ceph mon services need an IP address that is reachable from all Ceph consumers. A Ceph mon only listens on a single IP (constraint from Ceph). It must be reachable from:
- the management node
- all Ceph servers
- all Ceph clients
Reference Setups
Single Network, Single Nic
A quick and easy way to evaluate croit is to deploy it with only a single network. This setup works with servers that only have one NIC that is used for both management and storage traffic.
We do not recommend this for production deployments, but it’s great for a quick proof-of-concept setup on real hardware.
Configuration:
- Single NIC in each server connected to an access port (no VLAN tags)
- Flat layer 2 network with all nodes
- Complete storage network managed by croit
Two Networks, Single NIC
To separate administrative, monitoring, and DHCP traffic from the storage traffic, it’s beneficial to use isolated layer 2 network segments.
With only one NIC, you can make use of 802.1Q VLAN tags to split traffic into different networks. You have to make sure that your network is capable to boot in such a case.
Configuration:
- Separate croit and Ceph IP networks
- Two VLANs, both accessible from the management node
- Single network port per server (hybrid port mode)
- Management VLAN needs to be untagged (native VLAN or similar configuration)
- Ceph VLAN tagged, VLAN tag configured for each server
Redundant Network, Two NICs
For production environments, we strongly suggest the use of a redundant network setup for increased performance and resilience.
This setup uses LACP (aka 802.3ad, bonding, port trunking, NIC teaming) to build a single logical link from multiple physical interfaces. The switches need to support this feature. The physical links should be connected to separate switches using MLAG (aka Virtual Chassis, MCLAG) to ensure operation in case of switch failures.
LACP is not supported during boot with common NICs. Hence, the switch needs to be able to bring up a single port of a link even if no LACP is configured on the other side. This setting is called “no lacp suspend-individual” in Cisco switches and “force up” in Juniper switches. You have to use a third NIC for a dedicated management network if your switch does not support this feature.
Configuration:
- 2x NICs, configured as LACP
- Switch ports configured as LACP (802.3ad)
- Fallback for LACP to allow PXE boot or third management NIC for booting
- Optional further traffic separation via VLAN tags
Need Help?
Please keep in mind that a reliable and fast network is crucial to get good performance and resiliency. Bandwidth is especially important to recover quickly from disk and server failures or when rebalancing data when scaling up your storage. Our customers often see Network Bandwidth spikes far beyond 100 Gbit/s total.
You can use QoS and ToS configurations to prioritize traffic if necessary.
Our consultants are well versed in networking and are happy to help with network planning. Contact us to discuss your requirements.
Storage Hardware
Of course, Ceph not only depends on a good network, a good hardware design is absolute mandatory. Therefore you should think twice before ordering hardware from your preferred vendor. We as croit don’t care about the vendor as well as we don’t care what hardware you want to bring in use within your storage cluster. But we can assure you, that a good choice will make your cluster running smooth and fast for a long time.
From our own history, we know that there are tons of bad hardware on the market. Sometimes you find some great looking SSD’s with a Datasheet performance of 2.5 GB/sec and you might think that’s fantastic! We learned it the hard way, that this is definitely not the performance indicator you need to take a look at. The mentioned SSD from a big company performed very poorly with just 2.8 MB/sec for Ceph Workloads! Therefore, please make sure that you get some test equipment and test your disks before ordering too many of them.
For databases or high performance, we would strongly advice the use of NVMe-only pools. This way you get way better access times and bandwidth. But this of course is expensive and might burst your budget.
Even if SATA disks are cheap and come with great capacity, we do not advice using them for anything other than backup reasons. You can make use out of SATA disks if you add an additional, exceptionally fast SSD as a journal drive. But this will bring additional bottlenecks that you might not be aware of. If you choose DB/WAL devices to speed up some HDDs, you have to choose NVMe with high IO and Bandwidth performance over long times. Usually you size the DB/WAL with 120 GB per HDD or Actuator and not more than 12 OSDs per device.
Reminder: If you lose your journal device, you lose all disks depending on that journal.
Hardware Builds
MON (Monitor) Nodes
For MON Servers, you can use any actual small system or a Virtual Maschine with some local storage. They only need some little RAM for their work in most cases. It should be enough to start with 32 GB of RAM, 4 CPU cores, and a single disk to save MON data (e.g. a 512 GB NVMe). There is nothing wrong with simply scheduling these resources on a storage node and deploying the MON service along with the OSDs.
OSD (Storage) Nodes
When it comes to a storage environment, you always need servers with lots of disks in order gain capacity. OSD servers need a good balance from disk count to cluster size. If you plan to install 5 servers, please don’t make the very bad decision of buying 24 Bay or even more Chassis. For clusters below 20 servers, we don’t suggest to build servers bigger than 12 drives. This is because performance might suffer and if you lose one server, a big percentage of the data needs to be restored. For NVMe-only servers, we found that 10 Bay in height of 1 Rack Unit is good for high performance clusters.
Memory Requirement for each storage is min 8 GB, better 10 GB per disk. If you build a 12x 14 TB Storage, you should add at least 128 GB of Ram. When your servers are running, you might see the memory not actively being used, but believe us, you need it during recovery and Linux uses free RAM for caching and therefore speed purposes.
CPU Requirement depends on the disk type. Most of the time these CPUs are not used, but to ensure fast recovery you should select a cost optimized state-of-the-art CPU. Each HDD-OSD should get its own Hyper-Threading thread. If you add 12 disks you should build a system with a single socket 6-8 core CPU with HT. If you choose SSDs, plan with 2-4 threads per disk and for high end NVMe with 4-8 threads of a modern CPU.
In addition there is the need for further services such as MON, MDS, RGW and the operating system.
Things you should avoid:
- Slow Chassis Backplanes: Very often they are a bottleneck and causing more problems than they solve.
- Raid Controllers: Just don’t even think about them other than to provide more SATA/SAS Disk connectors.
- Overpriced, overvalued “special” data center hardware. Mostly manufactured in the same factories, often only the names are changed to make them more expensive to sell. Of course, this only applies to equivalent components, not to fundamentally different components.
- Consumer low end disks with poor performance
Installation
Installing the croit storage management solution is quite simple. Login to your Linux-based management node with Docker installed and execute the following commands.
docker create --name croit-data croit/croit:latest docker run --cap-add=SYS_TIME -v /var/run/docker.sock:/var/run/docker.sock --net=host --restart=always --volumes-from croit-data --name croit -d croit/croit:latest
By default croit uses Ceph Quincy. If you want to use a different Ceph version, use the matching tag (e.g. `latest.pacific` to use Ceph Pacific). You can find a list of available tags at hub.docker.com.
croit is made available at http://[hostname|ip-address]:8080 or via https at https://[hostname|ip-address]:8443 (self-signed certificate, can be changed in the /config directory in the docker container).
The container needs access to the Internet to download server images.
Note: You can add the option -e HTTPS_PROXY=https://your.proxy.int.corp.com to the docker run command to configure a proxy if required.
Setting up croit
croit will guide you through the initial setup of your Ceph cluster.
Login
Login as admin with password admin.
Setup Management Interface
croit uses one network interface as management interface for all management communication from PXE boot to monitoring running servers.
You need to select the NIC that you want to use for initial DHCP and PXE boot.
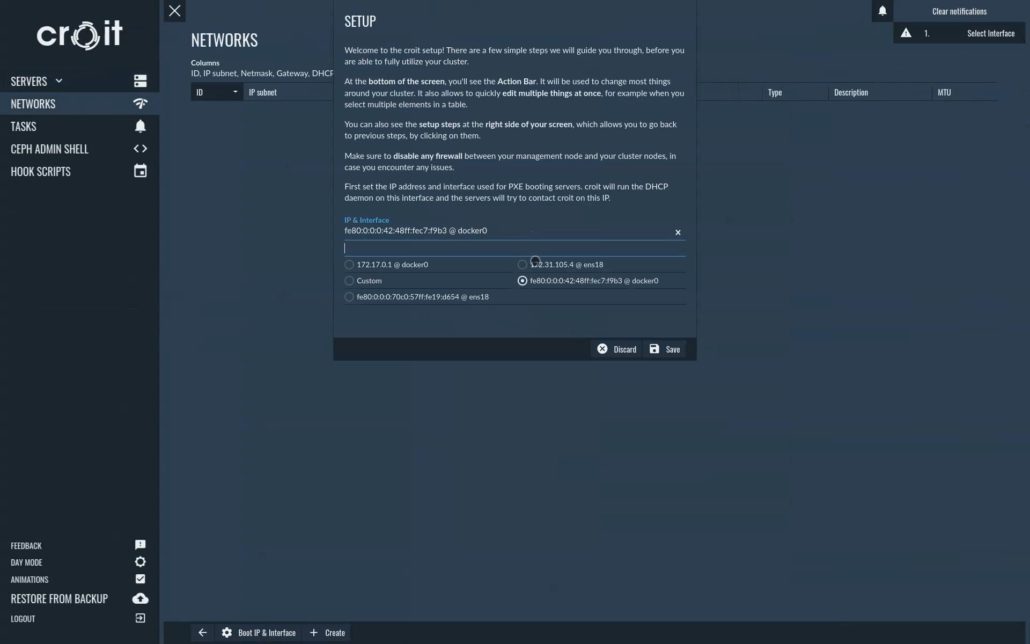
Setup PXE Network
Click create to open the dialog to setup your PXE network.
Configure the management network and set a DHCP pool to boot new servers.
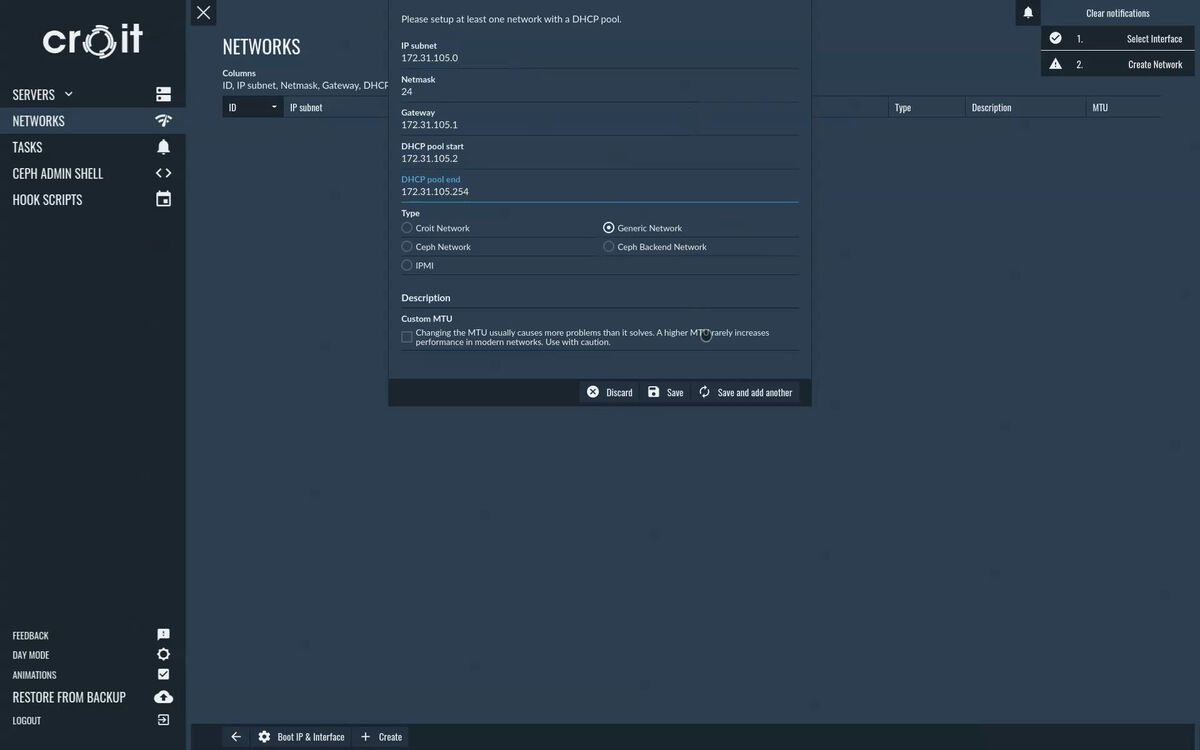
Depending on your network configuration, you need to configure further networks. In particular, you need to configure the network on which your initial monitor host resides in during setup. We recommend using multiple networks for a real setup, but a single network for all traffic is sufficient for proof-of-concept deployments.
Click Save to continue to the next step.
Boot the first server
Everything required to boot the first server is now configured.
Please make sure that you have configured PXE boot as first boot option from the correct NIC in the system’s BIOS/UEFI and power on the first monitor server.
Caution: Ensure that the Option ROM setting of the NIC you want to use is set to PXE.
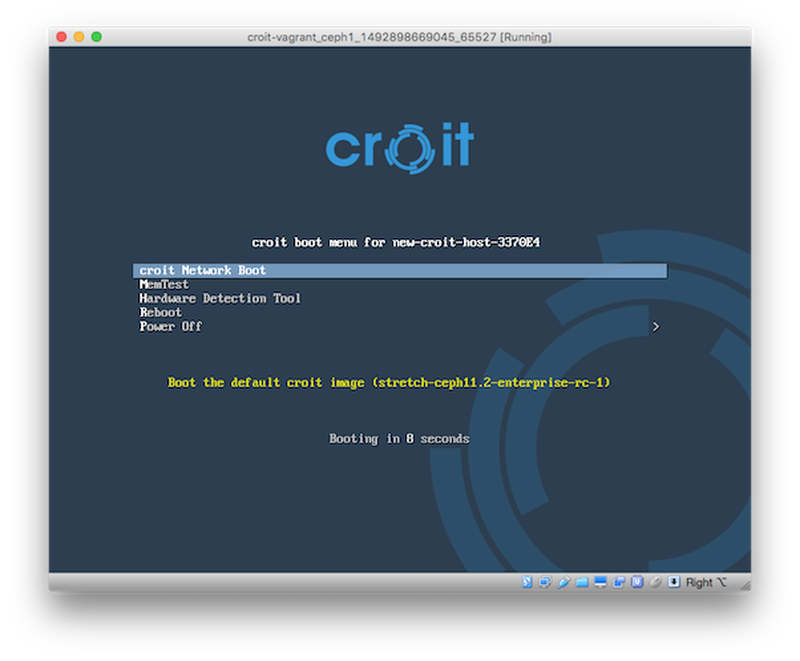
Caution: The live image is downloaded asynchronously from croit.io after the first start, the menu will instruct you to wait and retry if the download is not yet finished.
The server will automatically boot our live image and it will show up in our frontend as soon as you see the boot menu. Rename the server by setting the host name using the Edit button.
You can boot more servers the same way as your first server.
Configure a MON Disk
Disks and NICs will show up a few seconds after the server finishes booting. Configure an installed hard disk as Ceph mon. Mon disks are used to store the Ceph monitor database, each server running a Ceph monitor service needs one disk configured as mon disk.
Caution: We strongly recommend to use a small (50 GB is sufficient) but fast SSD for mons.
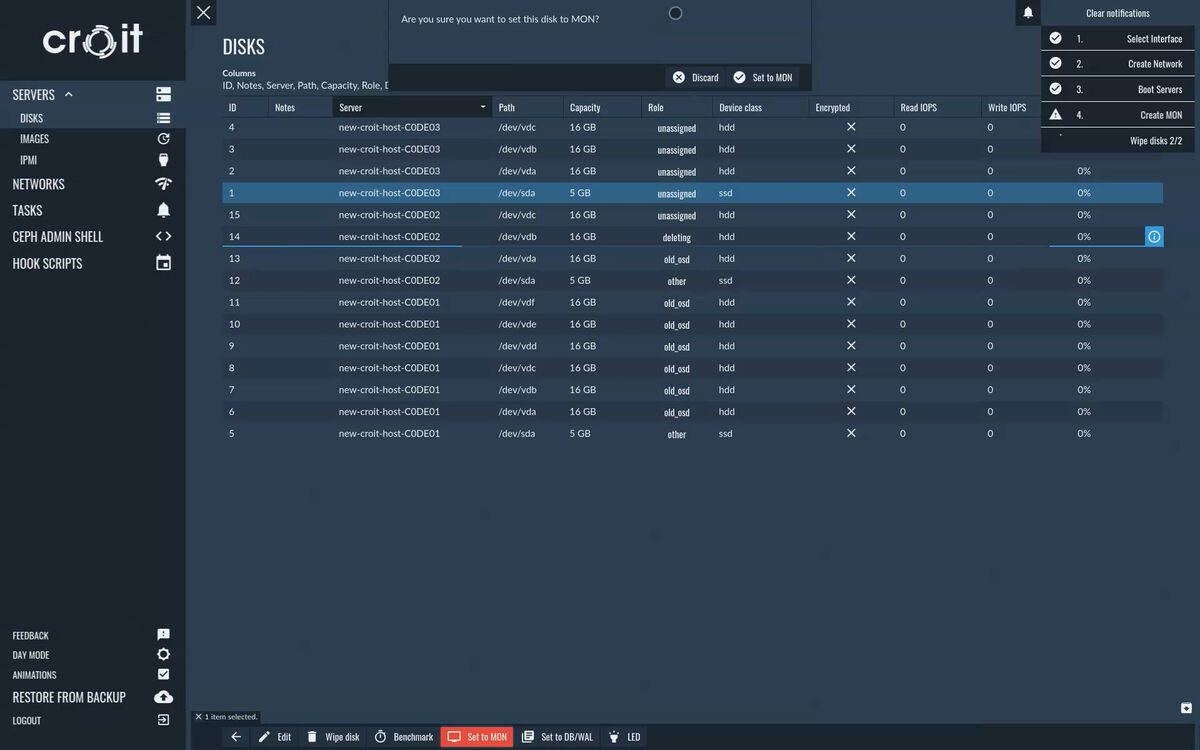
This formats and mounts the disk on the server, the ‘Set to MON’ button leading to the next step becomes active once this action completes successfully.
Create the Cluster
The last step is creating the Ceph cluster. Each server that was configured in the previous step can be selected as a MON.
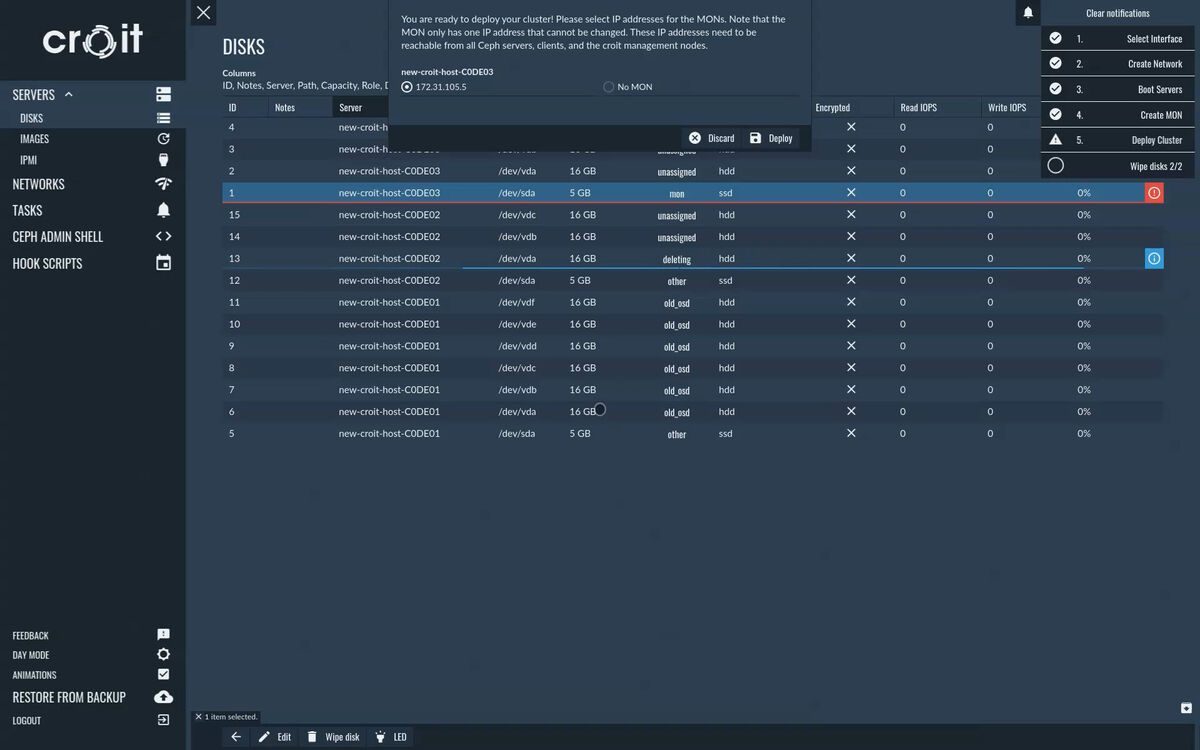
Caution: A Ceph monitor has exactly one IP address (even if the server has multiple IPs). This IP needs to be reachable by all Ceph services, clients, and the croit management daemon. You can go back to the previous step to configure further IP addresses or networks.
Adding OSDs
Our cluster starts out in an error state as we have not yet configured any disks to use for storage (OSD disks). Let’s get started by powering on the remaining servers for your cluster.
The servers will show up in the ‘Hardware’ tab where they can be renamed with the ‘Edit’ action.
Create OSDs on all servers by selecting ‘Disks’ followed by ‘Set to OSD’ on each disk, or select multiple disks and do a batch job. You can use external journal disks for OSDs by setting a disk’s role to journal before configuring OSDs on that server.
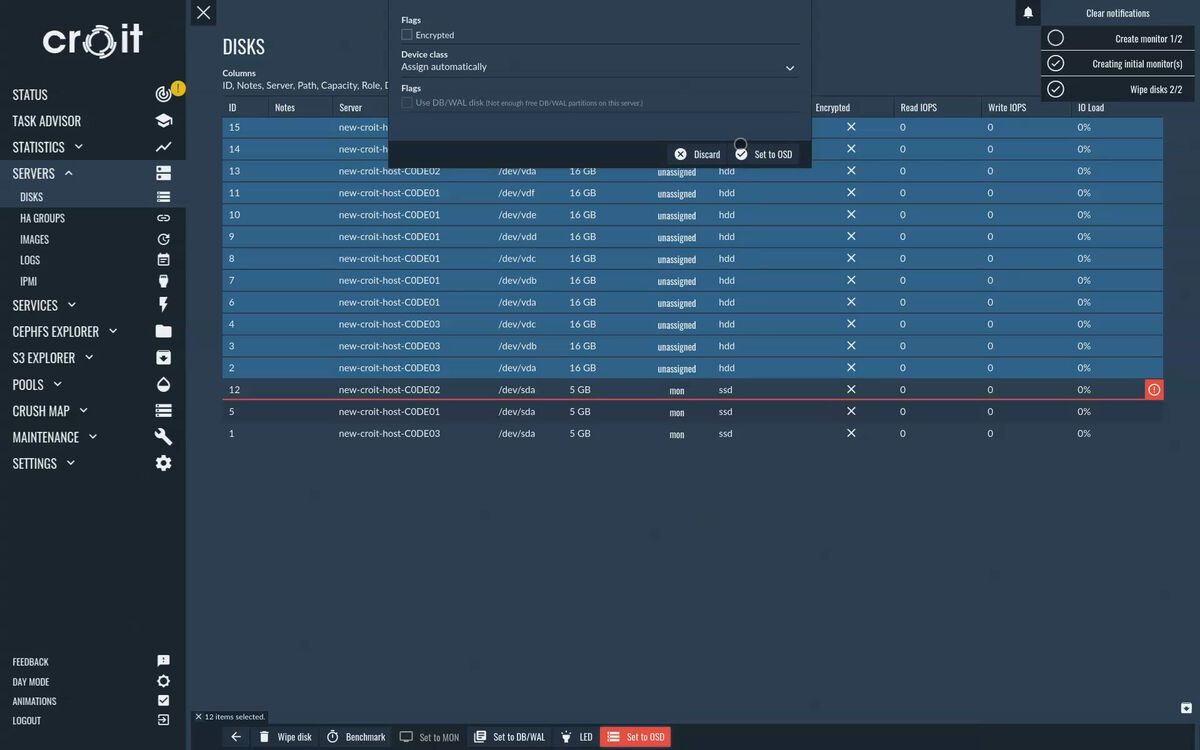
You can also click on ‘Disks’ below the table while not selecting any server to get an overview of all disks on all servers in a single view.
ADD HOSTS TO THE CRUSH MAP
On new clusters where we cannot detect any traces of Ceph, we automatically add the hosts to the crushmap.
After the initial deployment of a new cluster, croit does not automatically add new hosts to the crush map to avoid data movement before a server is fully configured. Select the CRUSH map tab and add the servers to the default root via drag and drop by dragging them at the drag indicator icon (=). Click ‘Save changes’ to update the crush map.
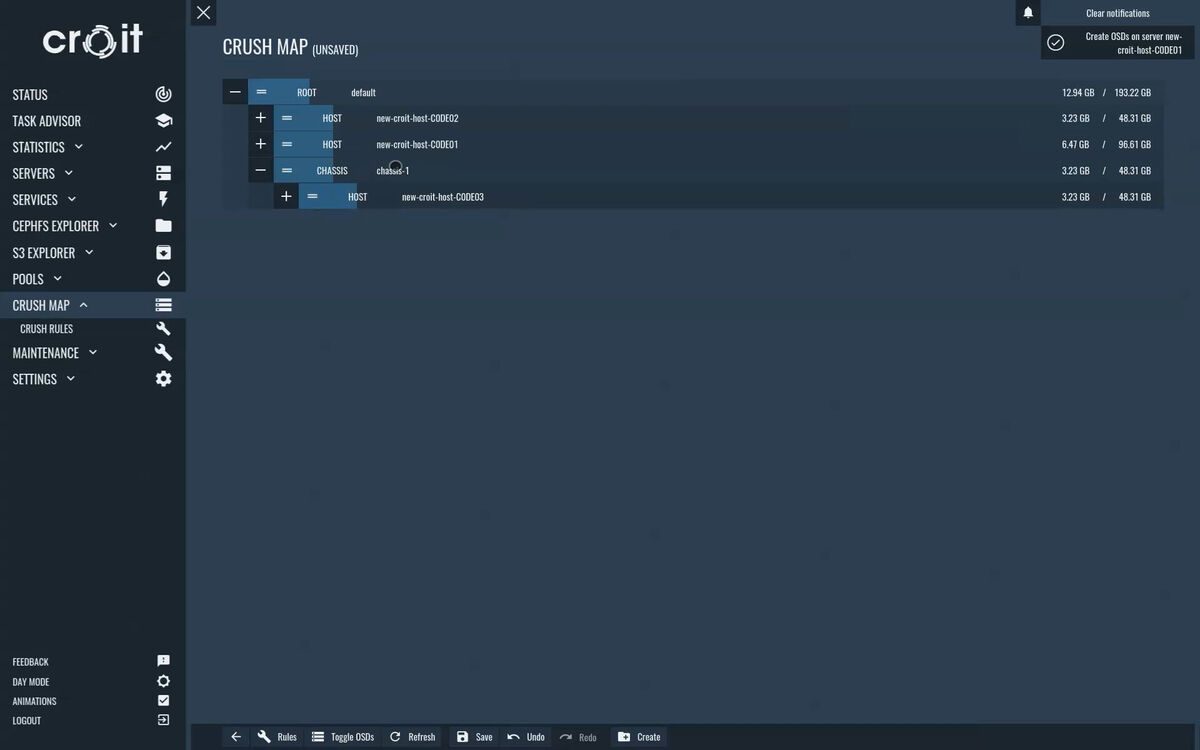
You can also add CRUSH buckets here to model your failure domains.
Adding additional MONs
Configure a disk as mon, then select ‘Show services’ to create an additional Ceph monitor service.
Keep in mind that there should be a odd number of mons for optimal fault tolerance. For production, a minimum of 3 MON Servers and a optimum of 5 MON Servers are required.
Further Services
You can configure further services as needed.
UPDATE YOUR CROIT SOFTWARE
If you are already using croit, we strongly recommend you to upgrade to croit latest. to get the best possible experience! Just enter the following two commands in the management node:
docker rm -f croit docker pull croit/croit:latest docker run --cap-add=SYS_TIME -v /var/run/docker.sock:/var/run/docker.sock --net=host --restart=always --volumes-from croit-data --name croit -d croit/croit:latest
Disclaimer: please make sure that you have a working backup before entering those commands.

